OpenAIはAzureのPostgreSQLのたった一つのプライマリインスタンスでどうやって8億のChatGPTユーザーをさばいているのか?
原文
https://openai.com/index/scaling-postgresql/
長い間、PostgreSQLはChatGPTやOpenAIのAPIなどのコア製品を支える重要な裏側のデータシステムのひとつでした。ユーザーベースが急激に拡大する中で、私たちのデータベースにかかる負荷も指数関数的に増加しています。過去1年で、PostgreSQLの負荷は10倍以上に成長し、今もなお急速に増え続けています。
この成長を維持するために本番環境のインフラ設計の強化を進める中で、新たな気づきがありました。それは、PostgreSQLが読み取り中心の大きな負荷に対して想定以上に信頼してスケールできるということです。PostgreSQL(カリフォルニア大学バークレー校の科学者たちのチームによって作られた)によってグローバルな大規模トラフィックに対応することができ、AzureのPostgreSQLのプライマリーインスタンス1つと、複数リージョンにまたがる約50個のリードレプリカでサービスが提供できています。
https://learn.microsoft.com/en-us/azure/postgresql/overview
この記事はOpenAIがどのようにしてPostgreSQLをスケールさせ、厳格な最適化と堅実なエンジニアリングによって、何百万ものクエリを毎秒処理できるようにしたかの物語です。途中で学んだ重要なポイントも紹介します。
初期設計の欠陥
ChatGPTのローンチ後、トラフィックは前例のない急激な伸びを見せました。それを支えるために、私たちはアプリケーションとPostgreSQLデータベースの両方で広範な最適化を迅速に実施し、インスタンスサイズの拡大とリードレプリカの追加によるスケールアウトを行いました。このアーキテクチャは長い間私たちにとって有効であり続けており、継続的な改善とともに今後の成長に十分な余力を提供し続けています。
一つのプライマリーアーキテクチャでOpenAIの規模に対応できるのは意外に思えるかもしれませんが、実際にこれを運用するのは簡単ではありません。私たちはPostgresの過負荷によるサービスダウンをいくつも経験しており、その多くは同じパターンをたどっています:アップストリームの問題により、キャッシュ層の障害からの広範なキャッシュミスや、CPUを飽和させる高コストのJOINクエリの急増、新機能リリース時の大量の書き込み処理などでデータベース負荷が急激に増加するケースです。リソースの利用率が高まるとクエリの遅延が増加し、リクエストはタイムアウトし始めます。リトライによって負荷がさらに増え、悪循環を引き起こしてChatGPTやAPIサービス全体の低下を招く可能性があります。
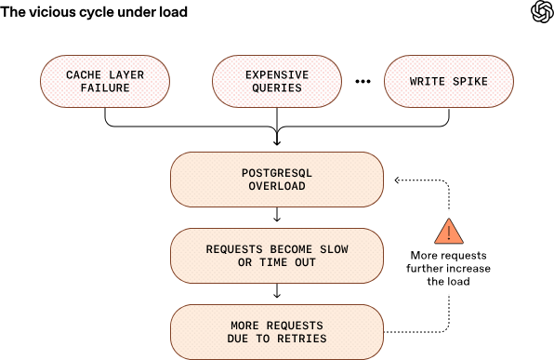
PostgreSQLは私たちの読み取り重視の負荷にはうまくスケールしますが、高い書き込み処理に対しては依然として課題に直面します。これは主に、PostgreSQLのマルチバージョン同時実行制御(MVCC)の実装に起因しており、このロジックは書き込み負荷が高い場合にはあまり効率的ではありません。例えば、クエリがタプルや単一のフィールドを更新すると、その行全体がコピーされて新しいバージョンが作成されます。高い書き込み負荷の下では、これが原因で書き込みには大きな負荷が生じます。また、クエリが複数のタプルバージョン(死んだタプル)をスキャンしなければならないため、読み取り処理も増幅します。MVCCは、テーブルやインデックスの膨張、インデックス管理のオーバーヘッド増大、複雑なautovacuumチューニングといった追加の課題ももたらします。(これらの問題について詳しくは、私がCarnegie Mellon UniversityのProf. Andy Pavloと書いたブログ「The Part of PostgreSQL We Hate the Most」を参照してください。)
https://www.cs.cmu.edu/~pavlo/blog/2023/04/the-part-of-postgresql-we-hate-the-most.html
PostgreSQLを何百万QPSに拡張するには?
これらの制限を緩和し、書き込み負荷を軽減するために、シャーディング可能(すなわち水平分割可能な処理)な書き込み処理を選別し、その中で特に処理が重いロジックをAzure Cosmos DBなどのシャーディング可能なシステムに移行し続けています。そして、アプリケーションロジックを最適化して不要な書き込みを最小限に抑えています。現行のデータベースに新しいテーブルを追加する事さえ、もはや許可していません。新しい処理は既定でシャーディングされたシステムに配置されます。
インフラストラクチャは進化しましたが、PostgreSQLのデータベースは未だにシャーディングされておらず、単一のプライマリインスタンスで全ての書き込み処理を捌いています。主な理由は、既存のアプリケーションのロジックの全てを水平分散した形に修正することは非常に複雑で時間がかかるためです。多くのアプリケーションエンドポイントに変更を加える必要があり、数か月から場合によっては数年かかる可能性もあります。私たちの処理は読み取りが主であり、広範な最適化も施しているため、現在のアーキテクチャのままでも継続的なトラフィックの増加を十分にサポートできる余裕があります。将来的にPostgreSQLのシャーディングを検討する可能性は排除しませんが、現在の設計でもまだ十分に余裕があるため、優先順位は高くありません。
この後のセクションでは、直面した課題や、それらに対応し将来の障害を防ぐために実施した徹底した最適化について詳しく掘り下げ、PostgreSQLの限界に挑み、秒間数百万のクエリ(QPS、Query per secondの略)にスケールさせる取り組みについて説明します。
プライマリーへの負荷軽減
課題:たった一つのライターだけでは、シングルプライマリの設定では書き込みのスケーリングが難しいです。急激に大量の書き込み処理が発生してしまうと、プライマリに過剰な負荷がかかり、ChatGPTや私たちのAPIなどのサービスに影響を及ぼすことがあります。
解決策:私たちは、プライマリの負荷をできるだけ最小限に抑えることに努めています。これには、読み取りと書き込みの両方を含みます。可能な限り、読み取り処理はレプリカで実行しています。ただし、一部の読み取りクエリは書き込みトランザクションの一部であるため、プライマリに残しています。そうしたクエリについては、効率的に処理し、遅いクエリを避けることに重点を置いています。書き込みトラフィックに関しては、並列に処理可能で書き込み負荷の高いワークロードをAzure CosmosDBといったシャーディングシステムに移行しています。シャーディングが難しいが高い書き込み量を生むワークロードの移行にはより時間がかかっており、その作業は引き続き進行中です。また、アプリケーションの最適化も積極的に行い、書き込み負荷を削減しています。例えば、冗長な書き込みを引き起こすバグの修正や、トラフィックの急増を緩和するために適切な場面での遅延書き込みの導入などです。さらに、テーブルの列の値を特定の値で埋める際には、過剰な書き込みを防ぐために厳格なレート制限も設けています。
クエリの最適化
課題: PostgreSQLのいくつかの高コストクエリを特定しました。過去には、これらのクエリの突然のボリューム増加によりCPUの消費が増大し、ChatGPTやAPIリクエストの遅延を招いていました。
解決策: 多くのテーブルを結合するなどの高コストなクエリは、サービス全体のパフォーマンスを著しく低下させたり、ダウンさせたりする可能性があります。PostgreSQLクエリの最適化を継続的に行い、効率的に保ち、一般的なOnline Transaction Processing(OLTP)のアンチパターンを避ける必要があります。例えば、12テーブルを結合した非常にコストのかかるクエリを過去に特定しましたが、そのスパイクが大規模なサーバーダウンの原因となったことがあります。複雑な複数のテーブルの結合はなるべく避け、必要な場合はクエリの分割や複雑な結合ロジックをアプリケーション層に移すことを学びました。こうした問題の多くはObject-Relational Mapping(ORM)フレームワークによって生成されるため、生成されるSQL文を注意深くレビューし、期待通りに動作しているか確認することが重要です。また、PostgreSQLでは長時間アイドル状態のクエリもよく見られるため、idle_in_transaction_session_timeoutなどのタイムアウト設定は、これらのクエリがPostgreSQLのAutovacuumを妨げるのを防ぐために必要です。
単一障害点への対策
課題:リードレプリカがダウンした場合でも、トラフィックを他のレプリカにルーティングすることは可能です。しかし、シングルライターに依存するということは、単一障害点を持つことを意味します。もしそれがダウンすれば、全てのサービスに影響が及びます。
解決策:ほとんどの重要なリクエストは読み取りクエリを伴います。プライマリのシングルポイント障害を軽減するために、その読み取り処理をライターからレプリカに移動して、プライマリがダウンしてもこれらの読み取りリクエストが正常に実行されるようにしています。書き込み操作は引き続き失敗しますが、その影響は軽減され、読み取りが利用可能である限り深刻なサービスダウンではなくなります。
プライマリ障害に備えるために、プライマリをHigh-Availability(HA)モードで運用し、ホットスタンバイを保持しています。これは常に同期されたレプリカで、サービストラフィックの引き継ぎにすぐ対応できる状態です。プライマリがダウンしたり、メンテナンスのためにオフラインにする必要がある場合でも、スタンバイを迅速に昇格させることでダウンタイムを最小限に抑えられます。Azure PostgreSQLチームは非常に素晴らしい仕事をしていて、これらのフェイルオーバーを非常に高負荷の状況下でも安全かつ信頼性高く維持できるようにしてくれています。リードレプリカの障害に備えるために、各リージョンに十分な容量余裕を持った複数のレプリカを配置し、単一レプリカの障害がリージョン全体の停止につながらないよう対策しています。
処理の分離
課題: よくあることですが、特定のリクエストがPostgreSQLインスタンスのリソースを過剰に消費してしまい、他の処理のパフォーマンスが低下するケースがあります。例えば、新機能のリリースに非効率なクエリが存在し、PostgreSQLのCPUリソースを大量に使ってしまい、その結果、他の重要な機能へのリクエストの処理速度が遅くなることがあります。
解決策: この「食いつくしおじさん」問題に対処するためには、処理を専用のインスタンスに分離して、リソースを大量に消費する突発的なリクエストが他のトラフィックに影響しないようにします。お皿を分けてその人が食べる分だけ置いておくような感じです。具体的には、リクエストを低優先度と高優先度に分類し、それぞれを別のインスタンスに振り分けます。これにより、たとえ低優先度の処理でリソースを使い果たす事になったとしても、高優先度のリクエストのパフォーマンスに影響を与えることはありません。この戦略は、異なるプロダクトやサービス間(ChatGPT、API、Sora)でも適用しており、ある製品のアクティビティが他の製品のパフォーマンスや信頼性に影響を及ぼさないようにしています。
Connection pooling
課題: 各インスタンスには最大接続数制限(Azure PostgreSQLでは5,000)があり、接続数を使い切ったりアイドル状態の接続が増えすぎたりすることがあります。過去には大量の接続が発生したことで利用可能な接続全てを使い果たしてしまうといった事例も発生したことがありました。
解決策: そのため、私たちはPgBouncerをプロキシ層として導入し、データベース接続をプーリングしています。StatementまたはTransaction poolingモードで運用することで、効率的に接続を再利用でき、アクティブなクライアント接続数を大幅に削減しています。これによって、接続確立のレイテンシも短縮され、ベンチマークでは平均接続時間が50ミリ秒(ms)から5 msに減少しました。リージョン間の接続やリクエストはコストが高くなるため、プロキシ、クライアント、レプリカを同じリージョンに配置し、ネットワークのオーバーヘッドと接続使用時間を最小限に抑えています。さらに、PgBouncerの設定も丁寧に行う必要があります。アイドルタイムアウトなどの設定は、接続の枯渇を防ぐために非常に重要です。
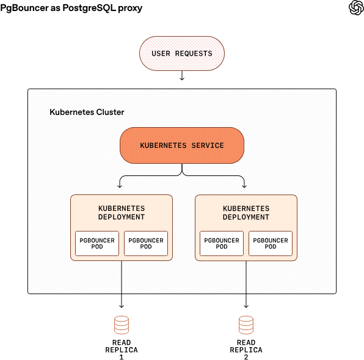
各リードレプリカには、それぞれ複数のPgBouncerポッドを運用するKubernetesデプロイメントが存在しています。同じKubernetes Serviceの背後に複数のデプロイメントを配置し、トラフィックを各ポッドに負荷分散しています。
Caching
課題:キャッシュミスが急増すると、PostgreSQLデータベースに対して大量の読み取りリクエストが発生し、CPUが飽和してユーザのリクエストの遅延を引き起こすことがあります。
解決策:PostgreSQLへの読み込み負荷を軽減するために、キャッシュ層を設けてほとんどの読み取り処理をそこで実行しています。ただし、キャッシュヒット率が突然低下した場合、キャッシュミスの突発的な増加によって、多くのリクエストが直接PostgreSQLに送られることになります。このデータベースへのリクエストの急増はシステムリソースを大量に消費し、サービスの遅延を招きます。このようなキャッシュミスの急激な増加に対処するために、キャッシュロッキング(およびリース)機構を導入し、特定のキーに対してミスした一つのリクエストだけがPostgreSQLからデータを取得し、キャッシュを再構築できるようにしています。同じキャッシュキーに対して複数のリクエストがミスした場合、ロックを取得した一つのリクエストだけがデータを取得し、キャッシュの再構築を行います。その他のリクエストは、キャッシュが更新されるのを待つ状態となり、一斉にPostgreSQLにアクセスすることを防ぎます。これにより、不要なデータベース読み込みを大幅に削減し、システムの過負荷を防止します。
リードレプリカをスケールする
課題:主要なストリームであるWrite Ahead Log(WAL)データをすべてのリードレプリカに送信しています。レプリカの数が増えるほど、プライマリはWALをより多くのインスタンスに送信しなければならず、ネットワーク帯域幅やCPUに対する負荷が増加します。これにより、レプリカがより遅延しやすくなり不安定になるため、システムのスケーリングが難しくなります。
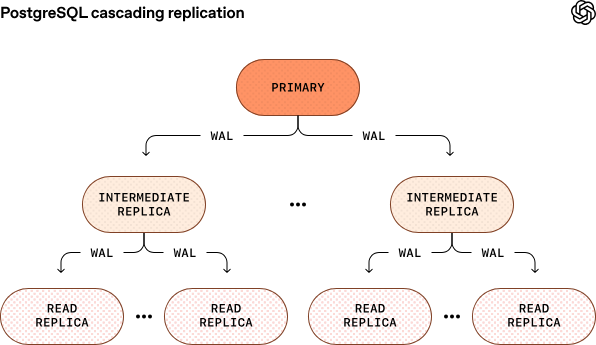
解決策:私たちは、レイテンシを最小限に抑えるために、複数の地域にわたって約50のリードレプリカを運用しています。しかし、現行のアーキテクチャでは、プライマリがすべてのレプリカにWALをストリーミングしなければなりません。非常に大きなインスタンスを使用しさらに高速なネットワーク帯域幅で運用することで現在は良好にスケールしていますが、インスタンス数を無制限に増やし続けることはできず、最終的にはプライマリに過剰な負荷がかかってしまいます。この課題に対処するために、Azure PostgreSQLチームと連携し、cascade型レプリケーションを導入しています。
https://www.postgresql.org/docs/current/warm-standby.html#CASCADING-REPLICATION
この仕組みでは、途中のレプリカがWALを伝達し、子のレプリカに渡すことが可能です。このアプローチにより、プライマリに過負荷をかけずに100以上のレプリカにスケールすることも視野に入れることができます。ただし、この方法は運用の複雑さを増し、フェイルオーバー管理に関して特に注意が必要です。現在もテスト段階にあり、安定性と安全なフェイルオーバーが確保できることを確認し次第、本運用に展開してまいります。
レート制限
課題:特定のエンドポイントで突発的なトラフィック増加や高額なクエリの急増、大量のリトライが発生すると、CPUやI/O、接続数などの重要なリソースが急に枯渇し、サービス全体に影響を及ぼすことがあります。
解決策:私たちは、アプリケーション、コネクションプーラー、プロキシ、クエリといった複数の層でレート制限を導入し、突発的なトラフィック増加によるデータベースインスタンスの過負荷や連鎖的な障害を防いでいます。また大量のリトライ処理を発生させないために、リトライ間隔の設定値を短くしすぎないことも重要です。さらに、ORMレイヤーにレート制限の仕組みを実装し、必要に応じて特定のクエリを完全にブロックする仕組みも導入しています。この特定クエリをブロックして過負荷から素早く脱出できる機能があるおかげで、高負荷なクエリの突発的な増加から迅速に回復できるようになっています。
スキーマの管理
挑戦:テーブルの列の型の変更などの小さなスキーマ変更でも、全テーブルの書き換えを引き起こす可能性があります。
https://www.crunchydata.com/blog/when-does-alter-table-require-a-rewrite
そのため、スキーマ変更は慎重に行い、軽量な操作にとどめ、全テーブルを書き換える可能性がある操作は避けています。
解決策:許可されるのは、特定の列の追加や削除などの軽量なスキーマ変更のみです。これらは全テーブルの書き換えを引き起こしません。スキーマ変更には厳格な5秒のタイムアウトを設定しています。インデックスの作成や削除は並行して実行可能です。スキーマ変更は既存のテーブルに限定しています。新機能で追加のテーブルが必要な場合は、Azure CosmosDBなどの代替のシャーディングシステムを使用し、PostgreSQLを避ける必要があります。(列の追加などで)テーブルの列を特定の値で更新する場合は、書き込み処理のスパイクを防ぐために厳格なレート制限を設けています。このプロセスには時には一週間以上かかることもありますが、安定性を確保し、プロダクションへの影響を防ぐことが目的です。
これまでの結果とこれからの展望
この取り組みは、適切な設計と最適化を行うことで、Azure PostgreSQLが世界最大規模の本番環境の負荷に対応できることを示しています。PostgreSQLは読み込みリクエストが多い負荷の高いワークロードに対して、何百万QPSもの処理能力を持ち、OpenAIのChatGPTやAPIプラットフォームといった最も重要な製品に活用されています。私たちはほぼ50のリードレプリカを追加しながら、レプリケーションの遅延をほぼゼロに保ち、地理的に分散したリージョンで低遅延の読み込みを維持しつつ、今後の成長に備えた十分なキャパシティの余裕も確保しました。
このスケーリングは、遅延を最小限に抑えながら信頼性も向上させることを両立しています。実際、私たちは常にクライアント側のp99でミリ秒単位の低い遅延と、プロダクション環境での5ナインの可用性を実現しています。
https://zenn.dev/atsushimemet/articles/d186552200b1bc
https://stackoverflow.com/questions/12808934/what-is-p99-latency
そして過去12ヶ月間で、SEV-0(最も深刻なレベルの障害)のPostgreSQLインシデントは一度だけでした(これはChatGPT ImageGenのリリース時に発生し、口コミもあって一週間で1億以上の新規ユーザーが登録し、書き込みトラフィックが突然10倍以上に急増した際の出来事です)
PostgreSQLが私たちのシステムをここまで支えてくれたことには満足していますが、今後の成長に備えるためにその限界にも挑戦を続けています。すでに書き込みが多いシャード可能なワークロードはCosmosDBのようなシャードシステムに移行しています。残っている書き込みの多いワークロードはシャード化がより困難であり、これも引き続き移行を進めて、PostgreSQLのプライマリから書き込みをさらに負荷分散していきます。また、Azureと連携しながらWAFのカスケードを可能にし、より多くのリードレプリカへ安全にスケールアウトできるよう調整しています。
今後も、分散型PostgreSQLや他の分散システムの採用など、さらなるスケーリングのためのさまざまなアプローチを模索し続ける予定です。